Modular XAI
In illustration of A Modular Interface for Multimodal Data Annotations and Visualization
Use Cases
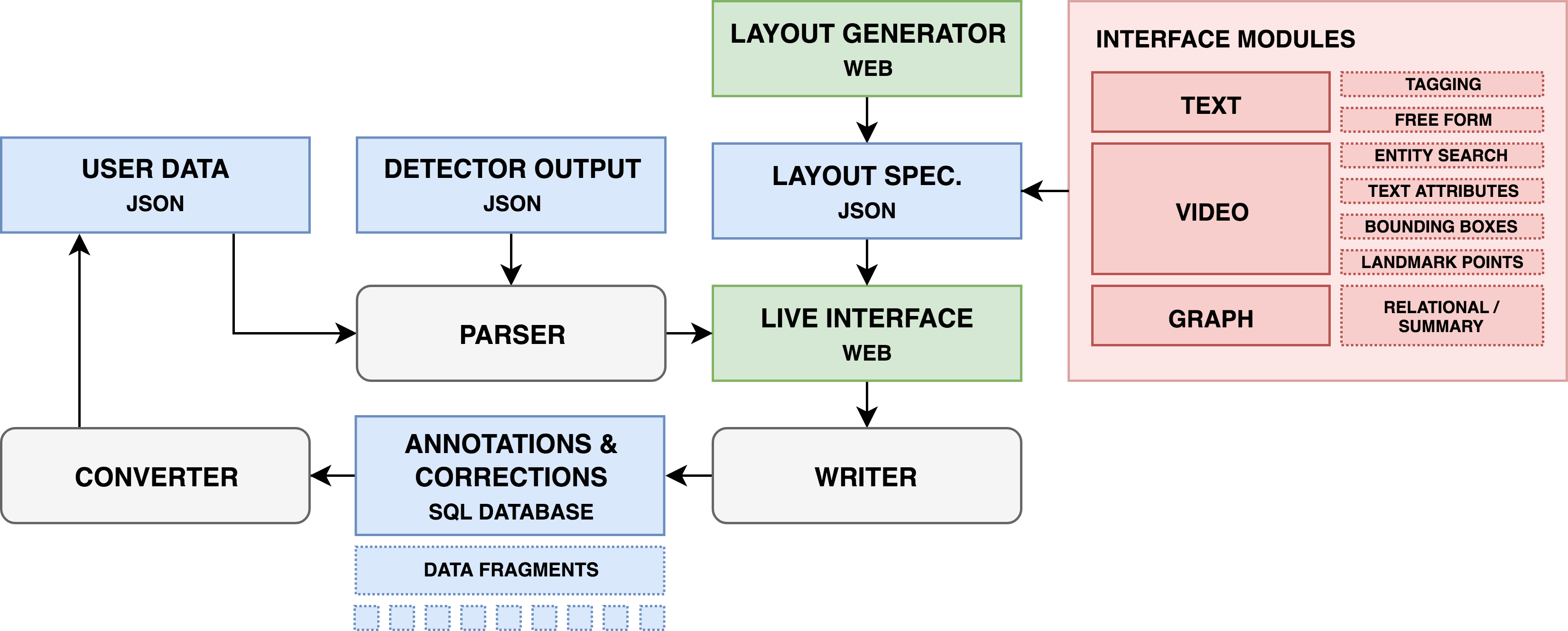
Abstract
We present a modular annotation and visualization tool for computational language and vision research. Our tool enables researchers to set up a web-interface for annotating new language and vision datasets, visualizing the predictions made by a machine learning model, or conducting user-studies. In addition, the tool accommodates many of the standard and popular visual annotations such as bounding boxes, segmentation, landmark points, temporal annotation and attributes, as well as textual annotations such as tagging and free form entry. It also includes a graph module to link visual and textual information. To further illustrate this, we showcase our interface applied to the MovieQA and MovieGraphs datasets.
Paper
The most recent version of the paper is available here.
Authors
University of Ontario Institute of Technology
Chris Kim (chris.kim@uoit.ca)
Christopher Collins (christopher.collins@uoit.ca)
University of Guelph and Vector Institute for Artificial Intelligence
Boris Knyazev (bknyazev@uoguelph.ca)
Graham W. Taylor (gwtaylor@uoguelph.ca)
SRI International
Tim Meo (tim.meo@sri.com)
Mohamed R. Amer (mohamed.amer@sri.com)